
0.基本概念
主键
- 数据表中的唯一索引,可以标识出数据表中的其他所有信息。不重复、不为空。
- 一张表中主键只有一个,但是可以包含多字段。(就是多个属性组成一个主键)
外键:
- 其他表的主键,可以重复,可以空。
- 作用:是为了保持数据的一致性,同别的表建立联系。
索引:就是数据库的数据结构。数据库中数据排列的方式,便于我们查询数据。最常见的B+树、红黑树等。
1.什么是数据库?(存放数据的仓库)
数据库是存储数据的仓库,本质上是一个文件系统。数据按照一定的格式存储在数据库内。
- 用户可以对数据库进行增、删、修、查等操作。(增加、删除、修改、查找)
- 数据的基本形式是表。
2.什么是数据库操作系统(管理数据库的软件)
数据库操作系统本质上是一个大型的软件,帮助我们管理数据库。对数据库的建立、修改、维护做统一管理。
- 我们通过数据库管理系统从而访问数据库中表中的数据。
3.数据库存储引擎(管理数据库的软件)
是数据库的底层软件框架,不同的数据库存储引擎提供不同的存储机制和索引技巧。改变数据库存储引擎就是更换了数据库的底层框架。
- MySQL的存储引擎有innodb和Mylsam。innodb提供了事务支持,是Mysql的显著特点。同时支持表锁和行锁。Mylsam只支持表锁。
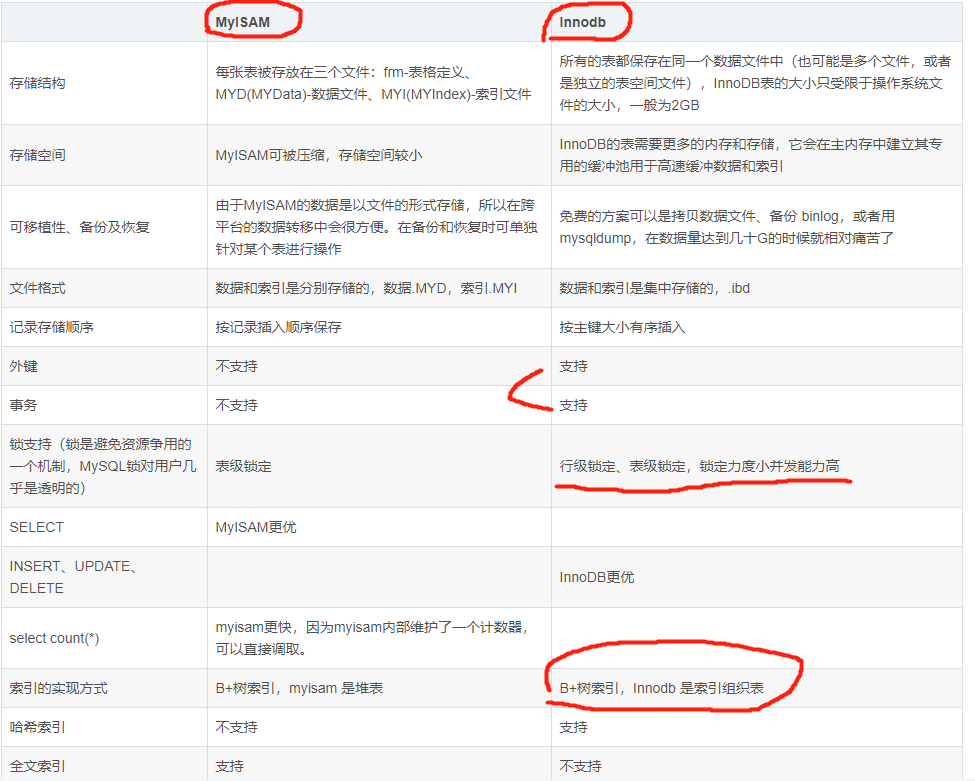
4.什么是关系型数据库和非关系数据库

关系型数据库:主要有:Mysql / Oracle / Sql Server / Sqlite
采用关系模型来构建数据的数据库。
最经典的数据结构是表,由二维表及其之间的联系组成一个数据组织。最大的特点是支持事务。
优点:易于维护,使用方便,支持事务。
缺点:海量数据查询效率低下、高并发读写时,硬盘的I/O是很大问题。(持久性到硬盘)
总结:易于使用,方便维护,支持事务。 / 并发读写效率低下

非关系型数据库:主要有:Redis / Hbase /MongoDB
- 采用非关系模型来构建数据的数据库。
- 一般用的较多的是键值对的形式来构建。一般不遵守事务ACID原则,结构不固定。
- 优点:格式灵活,查询速度快、成本低(无需直接写入硬盘,先从缓冲区寻找)
- 缺点:无事务处理,数据结构比较复杂
- 总结:不支持事务,数据结构复杂。但是查询迅速。
5.数据库中视图和表的区别
表是实际存在的数据,而视图是建立在表之上的,它依附于表,是展示表中数据的窗口。
试图可以对应一个表,也可以对应多个表。总体上是表的一个子查询,性能比直接查询高很多(存在内部优化)。但是不能嵌套查询,会大大增加开销。
区别:视图是编辑好的Sql语句,而表不是。
表是内模式,视图是外模式
视图没有物理记录
6.数据库中的三范式(表中数据的设计规范)
表中的数据遵守的设计标准,我们称为范式。只要有1NF、2NF、3NF、4NF、5NF。(关系模型)
同时设计标准满足向下兼容,高一级的范式必定遵守低一级的范式标准。
“关系模式”和“关系”辅助理解:关系模型是表的数据结构,而关系是具体的一张表。关系需要满足关系模型的设计要求。
第一范式:表中的字段不可再分。
第二范式:满足第一范式,同时非主键字段必须完全依赖于主键。
第三范式:满足第二范式,同时非主键字段之间不能存在传递依赖。
具体解释
- 第一范式

- 字段需要不可再分
- 缺点:满足第一范式的表数据还是存在很多冗余,会导致很多插入、删除、修改异常。
- 第二范式
名词解释:
函数依赖:类似于y = f(x),在X确定的情况下,只会对应计算出唯一的Y值。
- 完全依赖
- ID -> 姓名 / 唯一
- ID -> 学号 / 唯一
- 姓名 -> ID / 不唯一,存在重名等情况
- 我们称:姓名和学号完全依赖于ID
- 部份依赖
- (ID + 性别) -> 姓名 / 唯一
- 此时出现了冗余,一个ID就可以推出唯一的姓名,所以我们称姓名部分依赖于(ID+性别)
码(主属性):就是主键,可以包含一个或多个字段。
主属性:主键中的所有字段。
非主属性:除了主键中的字段外,其他的字段就是非主属性。
举例说明
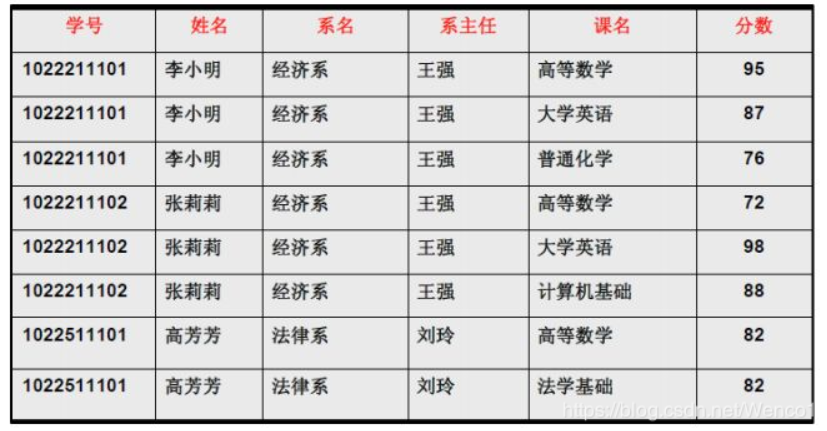
1.找到主键
2.确定主属性 / 非主属性
3.检验是否存在部分依赖情况
1.找主键(学号、课名)
2.主属性——学号、课名
3.非主属性——姓名、系名、系主任、分数
4.进行检验
学号、课名 ——>姓名
学号 ——>姓名 部份依赖
学号、课名——>系主任
学号 ——>系主任 部份依赖
总结:综上不满足第二范式,如何解决我们可以进行模式分解,将大表拆成多个小表。
缺点:满足第二范式虽然消除了很多冗余,但是还是存在一些问题。比如我们想插入一个新的学院,但是该学院还没有学生,这样主键是空的,所以不能插入元素。
- 第三范式:满足第二范式的基础上,同时非主键字段间不能存在传递依赖。只存在主键和非主键间的完全依赖。
主码为(学号,课名),主属性为学号和课名
- 非主属性只有一个,为分数
- 学号,课名 ——> 分数————满足
主码为学号,主属性为学号,非主属性为姓名、系名和系主任
- 学号 → 系名,
- 同时 系名 → 系主任——不满足
第一范式:表中的字段不可再分。
第二范式:满足第一范式,同时非主键字段必须完全依赖于主键。
第三范式:满足第二范式,同时非主键字段之间不能存在传递依赖。
7.数据库中的All关键字
- 特殊关键字
- 主键:primary key:表中的唯一索引属性
- 外键:foreign key references:其他表的主键,用于表之间的关联
- 不为空:no null

增、删、修关键字
create table ——创建一张表
drop table——删除一张表
insert into … values——插入一条信息
update …information…where ——更新信息
delete information ——删除信息
alter table … add——向表中添加某个字段
alter table … drop——将表中的某个字段删除
查询关键字
select B/ 表示要查找出的表所含有的属性
- distinct / 在select后加,表示结果去重
- all / 在select后加,表示结果不去重
from 表A / 表示要操作的表
where / 判断条件,根据该判断条件选择信息
- and / where中的判断条件,连起来
- or / where中的判断条件,多选一
- not / where中的判断条件,条件取反
多关系查找关键字
- A,B —— 在from的后面,表示连接多张表
- natural join —— 将两张表进行自然连接运算
- ——分为全连接(并)、左连接、右连接、内连接(交)(交并补)
- LEFT JOIN(左连接)
- RIGHT JOIN(右连接)
- 交并补——对于数据库来说
附加运算符
- as:将as前的关系起别名,这样表中可以用别名来指代这个表。——类似于浅拷贝
- *:表中的所有数据
- order by:对于查取的信息进行升序或降序排序
- desc:默认升序
- asc:降序
- between:查询两个数值中间的数值
- not between:between间数据的取反
- union / union all——对两个SQL语句做并操作,自动去重,加all不去重
- intersect / intersect all——对两个SQL语句做交操作,自动去重,加all不去重
- except / except all——对两个SQL语句做差操作,自动去重,加all不去重
- is null :在where中使用,表示这个值是空值
- is not null :在where中使用,表示这个值是不是空值
模糊查询 / where name like “%庄_”;
- Like:名称前面加。
- %:任意多个字符。
- _:下划线表示任意一个字符。
聚集函数
- avg
- min
- max
- sum
- count计数
- distinct对于数据进行去重
8.数据库中exists 和 in 的区别
in的判断类似于or,是将满足的子条件记录全部查询
exists 类似于一个子查询,然后进行bool判断是否查找到结果,有就返回true,没有就返回false
9.数据库中的底层数据结构
- 索引就是数据库中数据的排序结构。
- 一般的数据结构有平衡二叉树、红黑树、B树、B+树等。
- 常见的查找算法有顺序查找,二分查找法,哈希表散列法等。
MySql是持久化到硬盘的数据库,所以需要将数据读取到内存中。
磁盘读取数据到内存时,是以磁盘块(Block)为基本单位的,位于同一区域的数据会被全部读取出来。
所以根据磁盘读取的规则,读取次数越少,时间越快,消耗越少。所以当树的层级越少,枝节点保存的数据越多,这样查询的效率也就越高。
B树,单节点多Value值和索引指针,这样层数降低,单个节点保存的数据变多,读写次数更少。
B+树,只在叶子节点存数据,这样树的高度更低,同时单个枝节点存放的信息也更多,所以读取磁盘的时间更少。
B树则是提高了B+树的利用效率,当节点元素超过数量上限时需要分裂,而B树会优先去查询兄弟节点是否缺,同时也只会将1/3的元素放入下面的节点。
10. Redis和MySQL的区别?
a).mysql是关系型数据库,而redis是非关系型数据库。Mysql支持事务。而redis不支持事务。
b).Mysql是持久化数据库,每次访问都要在硬盘上进行I/O操作。频繁访问数据库会在反复连接数据库上花费大量时间。Redis则会在缓存区存储大量频繁访问的数据,当浏览器访问数据的时候,先访问缓存,如果访问不到再进入数据库.
总结:
Mysql持久性质,存到硬盘,读取慢,高频繁的IO导致效率很低。支持事务,结构稳定。
Redis缓存区存储大量频繁访问的数据,访问速度快,先访问缓存在去访问数据库。数据结构复杂,不支持事务。
11.数据库的索引和优化
索引定义:数据库中数据的排序方式。比如:平衡二叉树等等。
索引的优点:1.加快数据检索的时间
索引的缺点:1.索引的维护都需要时间,对数据的增删改查 2.索引需要占用额外的内存空间
12.数据库的锁
都是为了解决数据库并发控制的问题。确保多个事务存取数据的时候,不破坏事务的一致性和隔离性。
- 读锁/共享锁
- 写锁/排他锁
- 读写锁
- 意向锁——获得读写锁之前,需要
- 表锁
- 行锁
13.乐观锁和悲观锁
数据库的并发控制:确保多个事务存取数据的时候,不破坏事务的一致性和隔离性。
实现并发控制的主要手段有:乐观控制、悲观控制。——简单来说就是悲观锁、乐观锁。
定义:
悲观锁:在操作数据之前,对数据进行加锁。利用数据库锁的机制,保证事务间不会发生冲突。
- 包含读锁和写锁:对用户权限的控制
乐观锁:默认数据之间不会发生冲突,只在数据更新的时候对数据进行检测,如果发现了冲突,数据更新失败。没发现冲突,数据更新成功。
- 一般不使用数据库锁的机制:利用记录数据的版本来实现。
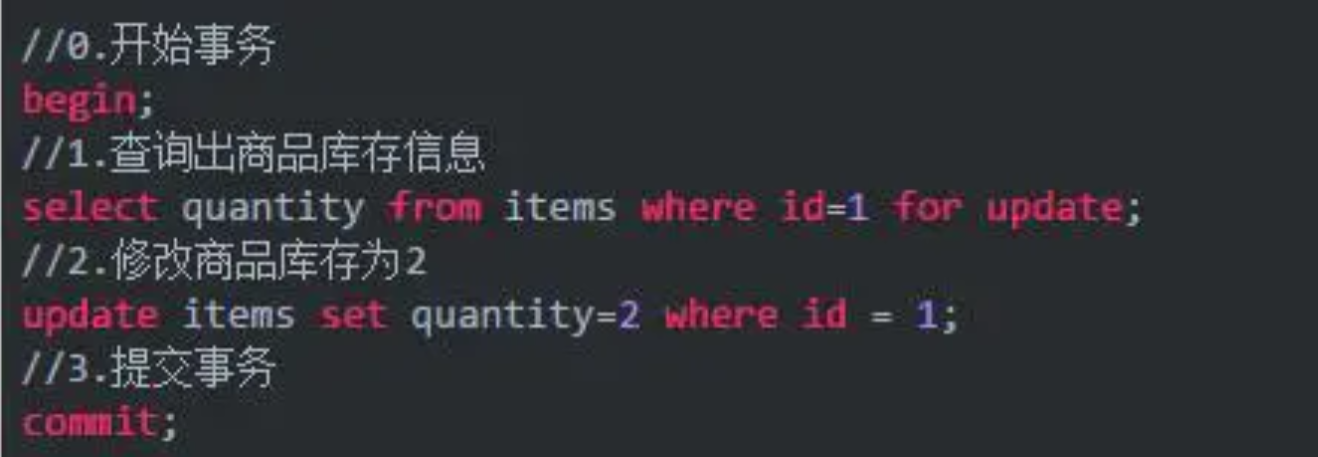
- 悲观锁:在Mysql中的事务处理中,会使用for update对数据进行锁定。然后对数据进行修改,保证数据的独享。

- 乐观锁:一般两个步骤,冲突检测,数据更新。典型的就是CAS算法:compare and swap。是一项乐观锁的技术。
- 检测数据版本,如果当前数据版本和之前不一样,那么就是数据过期了,需要予以更新。
- 简单来说就是当多个线程同时更新一个数据时,只有一个线程能够更新成功。其他的线程失败,失败的线程不会被挂起,而是被告知失败,可以再次尝试。
14.数据的事务
是对数据库内容的一个操作序列,是一个不可分割的单位。
- 事务结束的两种结果:(成功的事务提交、失败的事务回滚_撤销操作)
- 操作全部完成事务提交。
- 其中一个步骤失败,发生回滚操作,撤消该事务已执行的操作。
事务的四大性质ACID / 原子、一致、隔离、持久性。(Atomicity)/ (Consistency) / (Isolation)/(Durability)
- A_原子性:事务是不可分割的单位,只有0和1,要么成功,要么失败。
- 通过二进制日志文件来保证。将所有对数据的更新操作都写入日志,如果一个事务中的一部分操作已经成功,但以后的操作,由于断电/系统崩溃/其它的软硬件错误而无法继续,则通过回溯日志,将已经执行成功的操作撤销,从而达到“全部操作失败”的目的。
- C_一致性:事务前后数据保持一致性。需要符合逻辑运算。
- 通过原子性、隔离性、持久性来实现一致性。
- I_隔离性:并发的访问数据库时,事务间不能相互影响。
- 通过各种锁来实现:乐观锁、悲观锁等。从而解决脏读、不可重复读、幻读问题。
- D_持久性:事务提交后,对数据内容的更改是永久性的。持久性到硬盘,断开也不影响。
- 通过写入到硬盘来实现,而彼时redis的缓存区。
三种错误读取——方式
- 脏读——事务A,读取到了B事务未提交的数据,事务B回滚就产生了脏读。
- 不可重复读——重复读取数据时,前后读取的数据值不同。
- 幻读——读取到了别的事务刚刚插入的行数据,导致前后读取不同。
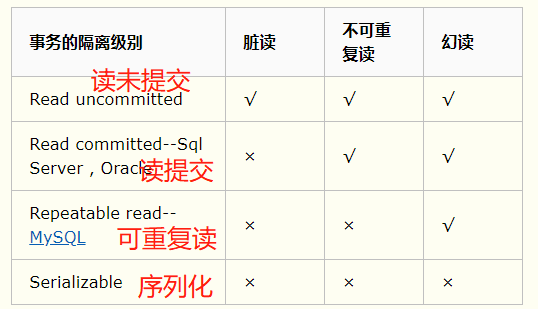
- 读未提交:读取到了别的事务未提交的数据。(读取到了其他事务未提交的数据)
- 一致性最差的,查询不加锁,产生脏读、不可重复读、幻读。
- 举例:
- 老板事务:发3000,但是发了30000,发现了产生回滚。
- 自己事务:发现余额30000,但是过了会,变成了3000,留下了贫穷的眼泪。

- 读提交:在同一个事务下,读取到的数据是不一样的。(前后两次读到的数据不同,数据被其他事务改写了)
- 可以避免脏读。但是还是会产生不可重复读、幻读。
- 举例:
- 自己事务:查询余额发现5000,准备消费2000。付款时查询发现还剩1000。
- 女朋友事务:败家老婆在这期间花了4000。

- 可重复读:在同一个事务下,不允许别的事务对自己的数据进行修改。
- MySql的默认隔离等级,但是还会产生幻读。
- 举例:
- 自己事务:事务1.消费了1000,事务2.之后消费了10000。
- 女朋友事务:事务1.后开启事务:发现消费1000,之后再次查询发现消费10000,读取到了新插入的新消费信息。

- 序列化:一致性最好的,但是效率极其差,同时开销也很大,一般不使用。
- 别人正在操作时,锁住整个表
- 总结:
- 读未提交:读到别的事物未提交的数据
- 读提交:在一个事务期间,读到的数据不一样。
- 可重复读:在一个事务期间,不允许对当前行数据进行修改。(行锁)
- 串行化:在一个事务期间,不允许对当整个表进行修改。(表锁)
15.MySql的binlog三种模式?(主站写、从站读)
MySql的二进制日志文件binlog。
- 以二进制形式记录更改数据库的SQL语句(insert,update,delete,create,drop,alter等)
- 用于Mysql主从复制
- 增量数据库的备份及恢复
一共有三种记录模式。(ROW:记录要修改的Value,Statement记录命令)
- Row模式:日志会记录每行数据被修改成的形式,然后在从端再对相同的数据进行修改,只记录要修改的数据,只有value,不会有sql多表关联的情况。
- 优点:记录数据详细(每行),主从一致
- 缺点:占用大量的磁盘空间,降低了磁盘的性能
- Statement模式:每一条会修改数据的SQL命令都会记录到master的binlog中,slave在复制的时候sql进程会解析成和原来master端相同的sql再执行。
- 优点:记录的简单,内容少
- 缺点:可能导致主从不一致
- Mixed模式:选择Row模式和Statement模式,二选一
- 普通操作使用Statement记录,当无法使用Statement的时候使用row。
16.Mvcc和 四种读的实现方式?
https://baijiahao.baidu.com/s?id=1669272579360136533&wfr=spider&for=pc
MVCC(Mutil-Version Concurrency Control),就是多版本并发控制。在数据库中,用来实现对数据库的并发访问,从而实现可重读的隔离等级。
- 一般可重读的隔离等级:用行锁来实现,
- 事务隔离的实现方案有两种,LBCC和MVCC
- LBCC:Based Concurrency Control,基于锁的控制
- MVCC:俗称快照读,为当前数据创建一个快照,后面就可以直接读取这个快照,读取的是数据的历史版本,而不是最新版本。没用到锁。
- 快照读,指的是在RR隔离级别下,在不加锁的情况下MySQL会根据回滚指针选择从undo log记录中获取快照数据,而不总是获取最新的数据。
- undo log:维护着历史数据
- DB_TRX_ID:最后一个事务的事务ID / DB_ROLL_PTR:回滚指针